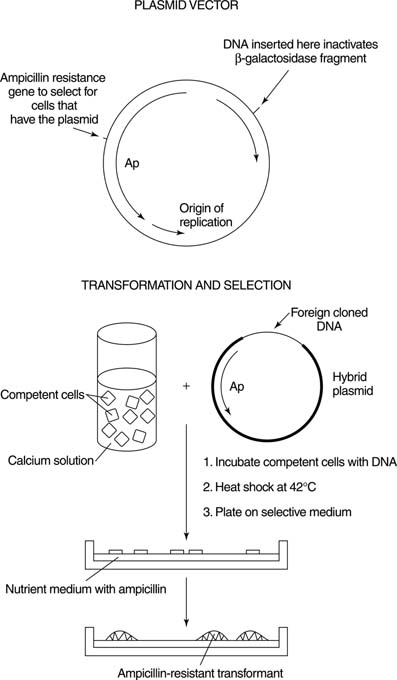
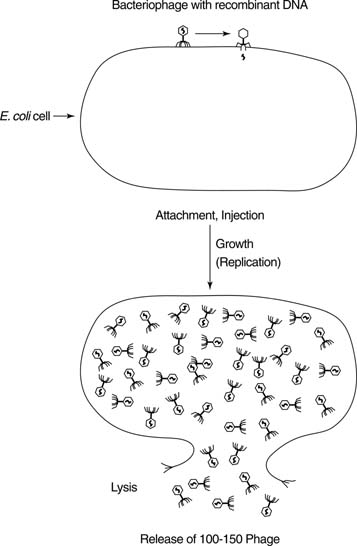
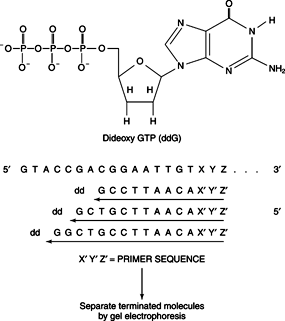
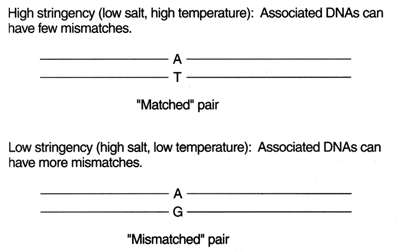
DNA: Deoxyribonucleic acid. The double-stranded chemical instruction manual for everything a plant or animal does: grow, divide, even when and how to die. Very stable, has error detection and repair mechanisms. Stays in the cell nucleus. Can make good copies of itself.
RNA: Ribonucleic acid. Single-stranded where DNA is double-stranded, messenger RNA carries single pages of instructions out of the nucleus to places they're needed throughout the cell. No error detection or repair; makes flawed copies of itself. Evolves ten times faster than DNA. Transfer RNA helps translate the mRNA message into chains of amino acids in the ribosomes.
[Diagram of RNA vs. DNA: chemical structure and composition]
Base: a building block of DNA and RNA. There are five different bases: Adenine, Thymine, Guanine, Cytosine, and Uracil (which is found only in RNA and replaces Thymine in DNA).
Ribosomes: Message centers throughout the cell where the information from DNA arrives in the form of messenger RNA. The RNA message gets translated into a form the ribosome can understand and tells it which protein building blocks it needs and in what order to assemble them. Ribosomal RNA helps the translation go smoothly.
Amino acids: Polypeptide (protein) building blocks.
Polypeptides: chains of amino acids. Proteins are made up of several or many polypeptides.
Proteins: Chemicals that make up cell and organ structure and carry out reactions throughout the body, from breaking down food to fighting off disease.

RNA: Ribonucleic acid. Single-stranded where DNA is double-stranded, messenger RNA carries single pages of instructions out of the nucleus to places they're needed throughout the cell. No error detection or repair; makes flawed copies of itself. Evolves ten times faster than DNA. Transfer RNA helps translate the mRNA message into chains of amino acids in the ribosomes.
[Diagram of RNA vs. DNA: chemical structure and composition]
Base: a building block of DNA and RNA. There are five different bases: Adenine, Thymine, Guanine, Cytosine, and Uracil (which is found only in RNA and replaces Thymine in DNA).
Ribosomes: Message centers throughout the cell where the information from DNA arrives in the form of messenger RNA. The RNA message gets translated into a form the ribosome can understand and tells it which protein building blocks it needs and in what order to assemble them. Ribosomal RNA helps the translation go smoothly.
Amino acids: Polypeptide (protein) building blocks.
Polypeptides: chains of amino acids. Proteins are made up of several or many polypeptides.
Proteins: Chemicals that make up cell and organ structure and carry out reactions throughout the body, from breaking down food to fighting off disease.
DNA is transcribed into mRNA which is translated into amino acids.
This is